

Василий Н.
-
Публикаций
5902 -
Зарегистрирован
-
Посещение
-
Дней в лидерах
5
Посетители профиля











-

Насколько оправдано применение рупора в современных акустических системах Hi-End?
Василий Н. ответил в теме пользователя DoctorZak в Акустические системы
Например, прототип JBL K2 S9900 (в серию не пошёл) "зарублен" маркетологами из-за отсутствия явных рупорных искажений. Впрочем, то что продаётся (JBL K2 S9900) имеет довольно малый рупорный окрас, через что не всем "любителям рупора" по вкусу. -
Насколько оправдано применение рупора в современных акустических системах Hi-End?
Василий Н. ответил в теме пользователя DoctorZak в Акустические системы
Как утверждает Сергей Агеев и я с ним согласен: "... характер "заполнения" пространства хорошим рупором на СЧ-ВЧ совершенно другой. Если у обычных головок диаграмма направленности с ростом частоты "схлопывается", компенсируя на оси падение акустической мощности (АЧХ при этом вроде как ровная, но доля диффузного поля с ростом частоты становится все меньше), то с рупорным драйвером, нагруженном на хороший рупор и "держащим" диаграмму направленности, соотношение прямого и диффузного звука получается гораздо стабильнее. В частности, поэтому звук действительно хорошего рупорника принципиально иной по характеру, намного ближе к естественному по "воздушности". IMHO, именно за это довольно многие люди нередко готовы простить сильную окраску, вносимую неравномерностью АЧХ и паразитными резонансами/отражениями у большинства реально существующих рупорных АС. "Неокрашивающий" рупор в принципе сделать можно, единичные примеры есть, но "повторяемые" решения мне не встречались. И разброс достаточно велик." -
Foobar 2000
Василий Н. ответил в теме пользователя Василий Н. в Цифровые источники и компьютерные технологии для аудио
Обновил собственную утилитку двукратного апсемплера (для 44,1/48 -> 88,2/96), добавив пороговую нормализацию с уменьшением общего уровня на 2 дБ при превышении пикового уровня входного файла в -0.3 дБ и на 0.25 дБ в остальных случаях для предотвращения межсемплового клиппинга. Пока самое "суровое" что попалось с межсемпловым клиппингом это "Feuer Frei!" с диска "Mutter" Раммштейн, там полдюжины скачков даже больше 2 дБ. Ещё слегка уточнил коэффициенты регрессии для фильтра апсемплинга по мере набора статистики. Выложил там же https://alesta.ru/Downloading/ (ссылкой на ЯД). На всякий случай, для файла ALESTA_16to24x2.exe контрольные суммы: SHA-1: 01D57957F9C34AE22568D844B2E84B0737940D2D MD-5: 03E922539C4E0082880F209086B3D3C3 -
Foobar 2000
Василий Н. ответил в теме пользователя Василий Н. в Цифровые источники и компьютерные технологии для аудио
На Вегалабе подсказали хорошее решение, реабилитирующее фубаровский foo_input_sacd плагин, а именно дополнительный фильтр от S-Audio.Systems . С ним отличие от результата конвертирования Saracon'ом становятся практически незаметными (чуть ниже уровень и сдвиг на пару семплов (88,2). С учётом скорости, универсальности и удобства Foobar - Must Have! Кстати, для пользователей Aplayer тоже подходит. -
Ну, протокол USB-Audio изохронный, а значит перезапрашивание пакета в случае ошибки - отсутствует (в отличии, например, в от передачи данных на флешку), через это вопрос bit-perfect того, что приходит на саму м/сх ЦАП далеко не праздный, а проверить не так просто.
-
Clearsound
Василий Н. ответил в теме пользователя Alexander M в Цифровые источники и компьютерные технологии для аудио
А если его ещё и настроить... -
Foobar 2000
Василий Н. ответил в теме пользователя Василий Н. в Цифровые источники и компьютерные технологии для аудио
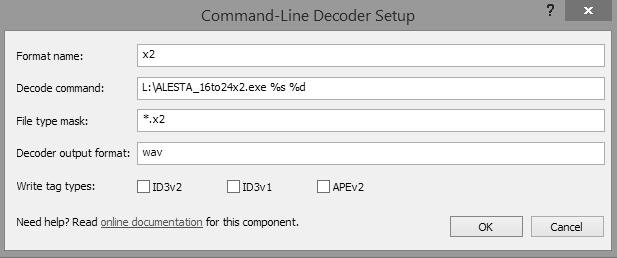
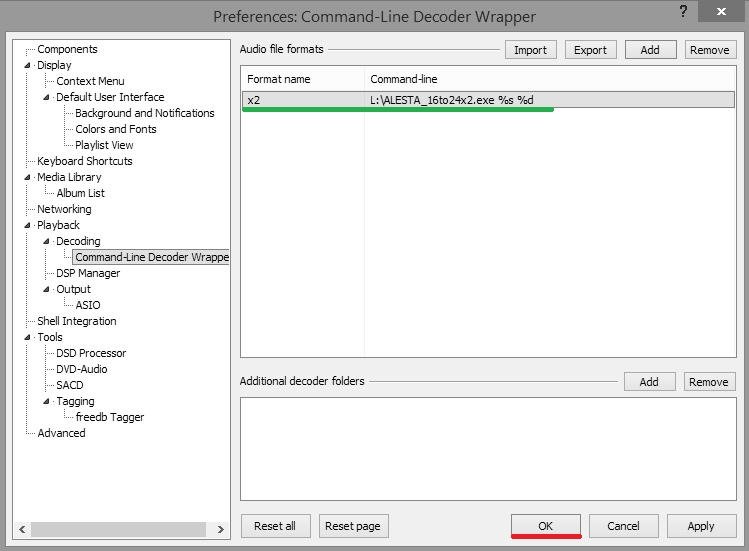
Попробовал . 1. скачать и установить плагин Command-Line Decoder Wrapper (https://www.foobar2000.org/components/view/foo_input_exe 2. зайти в File\Prereference\Command-Line Decoder Wrapper и добавить добавить пользовательскую программу/апсемплер. 3. настроить параметры вызова апсемплера: а) (задать название- любое); б) задать программу апсемплера , указав полный путь (если в названии пути есть пробелы- взять в кавычки) и обязательно указать параметры %s %d; в)задать расширение, по которому будут браться файлы апсемплером, для примера задал *.х2. К сожалению, файлы *.wav на апсемплер не передаются, с другой стороны, если все *.wav будут апсемплироваться, тоже не очень хорошо. 4. убедиться, что внешний апсемплер добавлен и подтвердить OK. Перед проигрыванием переименовать расширение звукового файла, на то, которое назначили формату (в примере на *.x2), т.е. был, например input.wav, необходимо input.x2 (или переименовать копию, дабы не трогать оригинал). После чего, (переименованный) открывать Фубаром как обычно. Ещё одна проблема подобного решения это Фубар не видит тэги таких переименованных файлов (есть вроде обход, но пока не изучал), так что я всё же предпочитаю пользоваться программой как внешним конвертором, предварительно создавая апсемплированный файл.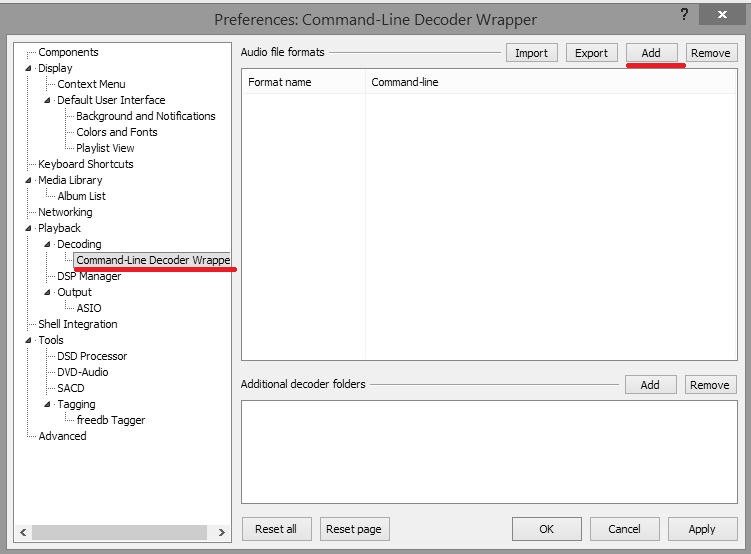
-
Foobar 2000
Василий Н. ответил в теме пользователя Василий Н. в Цифровые источники и компьютерные технологии для аудио
Расхождения будут, их не может не быть. Как минимум, рассчитанных (промежуточных) значений, а более вероятно - всех, из-за, например, разных алгоритмов конкретной реализации борьбы с возможным межсемпловым клиппом. Что же касается вычисленных промежуточных значений, то в различии между синтезированным строго математически с помощью, например, фильтра Найквиста и на основе статистической модели, то в их различии весь смысл и заключается. На основе статистической модели как бы делается такой своеобразный низкоуровневый дизеринг, слегка маскирующий цифровой шум. Засада в том, что однозначного предпочтения нет в зависимости о аудио-сетапа/предпочтений слушателя/контента (жанра, мастеринга). С другой стороны, есть выбор, но опять же, общую картинку даст только статистическое исследование, с которым серьёзные проблемы. Для сравнения, ссылка на результаты двукратного апсемплинга выше приведённого файла моей программой (с аппроксимацией и без) и прототипом (не моей) программы, реализующей фильтр Найквиста : https://yadi.sk/d/db-QgkBp_iPAsg?w=1 -
Foobar 2000
Василий Н. ответил в теме пользователя Василий Н. в Цифровые источники и компьютерные технологии для аудио
Проверил в аудио-редакторе: Оригинальный трек: Peak -0,З RMS -14,2 Апсемплер с аппроксимацией: Peak -0,8 RMS -14,7 Апсемплер без аппроксимации: Peak -0,8 RMS -14,7 т.е. снижение на ~0,5 дБ. Либо у вас ещё дополнительная обработка, либо апсемплировали не моей программой. -
Foobar 2000
Василий Н. ответил в теме пользователя Василий Н. в Цифровые источники и компьютерные технологии для аудио
Привет, Дима! Начал копать статистические методы, там бездны . Насчёт on-line - была такая мысль сделать страничку, где подгружаешь свой wav файл, а на выходе скачиваешь апсемплированный и/или аппроксимированный, но там возни многовато, да и отшлифовать надо этот конвертор. С Фубаром в виде файловой оболочки пока намного удобнее: в нём и другие аудиоформаты легко подтягивать, и альбомы / плей-листы сразу обрабатывать. Кстати, в Фубаре вроде есть возможность внешний конвертор, типа моего, как плагин "на лету" использовать, надо попробовать, но не уверен, что получится. -
Foobar 2000
Василий Н. ответил в теме пользователя Василий Н. в Цифровые источники и компьютерные технологии для аудио
Было бы интересно ознакомиться с оригиналом такого файла. -
Foobar 2000
Василий Н. ответил в теме пользователя Василий Н. в Цифровые источники и компьютерные технологии для аудио
Тут важно понять: по сравнению с чем изменится? Ну, и критерии "значащий для ЦАП бит" могут быть достаточно широки. Будут ли заметны изменения на слух, если меняется, допустим, каждый сотый младший (24-й) бит? А каждый тысячный? Причём с учётом статистических характеристик этих изменений и длины фильтра. -
Foobar 2000
Василий Н. ответил в теме пользователя Василий Н. в Цифровые источники и компьютерные технологии для аудио
Нет, постоянны, но получены усреднением 10 тыс. выборок розового шума. -
Foobar 2000
Василий Н. ответил в теме пользователя Василий Н. в Цифровые источники и компьютерные технологии для аудио
У меня ограничений на контроллер не было, да и вообще хотелось попробовать именно статистически вычисленные коэффициенты для регрессионной модели. Насколько помню, у тебя в PA20 не сигма-дельта ЦАП, но там тоже апсемплинг даёт заметный прирост в качестве? -
Foobar 2000
Василий Н. ответил в теме пользователя Василий Н. в Цифровые источники и компьютерные технологии для аудио
Захотелось поменять примитивный апсемплер на что-то более продвинутое. После сравнения фубаровского DSD-плагина с Saracon, решил присмотреться/прислушаться к апсемплерам, нет ли и там предпочтения удобству/скорости в ущерб качеству? Поизучал немного (фубаровские) апсемплеры и пришёл к выводу, что, скорее всего, так и есть, поскольку, по уму, как мне объяснили специалисты, надо делать программный апсемплер , реализуя найквистовский фильтр, а если считать честно, да ещё с плавающей точкой с двойной точностью, получается очень большой объём вычислений, с разницей по скорости примерно как у DSD-плагина Фубар с Saracon. Решил попробовать по другому, воспользоваться статистическими методами, а именно линейной регрессией. Даже замахнулся было на нейросеть, но быстро понял, что при требуемой величине «окна» необходимо использование свёртки, например, вейвлетами, так что остановился на линейной регрессии. Дополнительным преимуществом предлагаемого подхода является то, что вычисляются только промежуточные значения, а исходные не меняются (за исключением снижения общего уровня на ~ 0,5 дБ для уменьшения возможного межсемплового клиппинга), что позволяет довольно точно сохранять исходную фазу. Для вычисления коэффициентов регрессионной модели использовал розовый шум. Кому интересно, может заценить на своих треках/альбомах, скачав по ссылке там же: https://alesta.ru/Downloading/ .

